
This is a variation of “Be, Do, Have” (“Be, Do Have” == Be a photographer, Do take a bunch of photos, and then Have/Buy expensive equipment). It records my recent epiphany in Machine Learning. This variation is “Read, Do, Aha”.
I have read a lot of material on machine learning (linear regression, logistic regression, neural nets, supervised learning, CNNs, etc.) I have done some certifications (mainly from Coursera, from Andrew Ng, in the Machine Learning Specialization).
I have already completed the Convolutional Neural Networks course (fourth of the five of the Deep Learning Specialization) and recently decided to “go back” and start with the first course in this specialization – Neural Networks and Deep Learning.
In that course, one of the exercises is to build a simple neural net (simple = two layers total, no hidden layers). So simple it is equivalent to a Logistic Regression model. A very basic plot of a Logistic Regression model is:
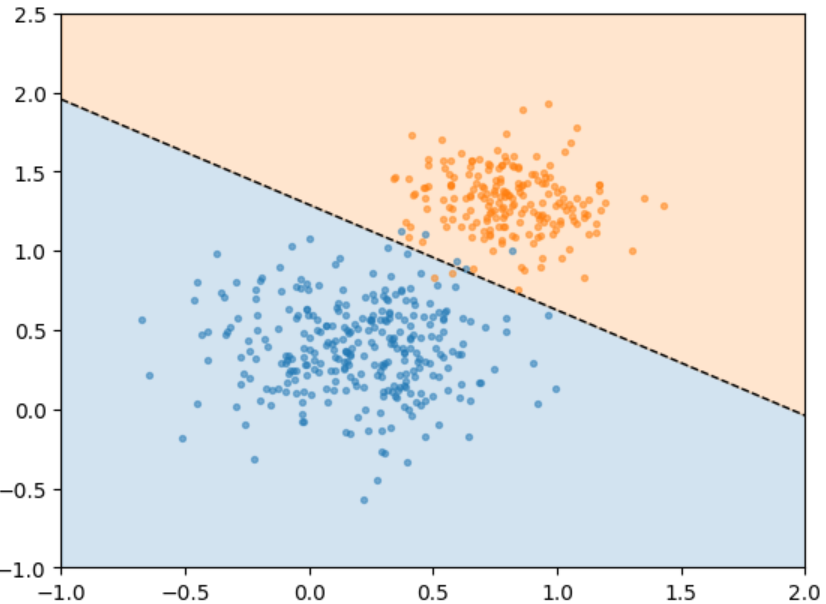
In the example above, two inputs (plotted above as x and y) are given a binary classification (blue dot or orange dot), and then a single-line regression is computed, and the graph shaded into blue and orange areas. Thereafter, you can use that line to test the accuracy of known (training) data, and to make predictions on never-seen-before (test) data. In the above example, the training accuracy is quite good, and it seems safe to say the test accuracy will/would be quite good as well.
The course uses “Cat or not-Cat” as the binary class definitions, and flattens a 64x64x3 image into a an input of 12,288 values. After everything is implemented and run against the training data, you have a 12,000+ dimension hyperplane that divides the input space into Cat/not-Cat.
The “Aha!” moment looks like this:
- Fact: It can be trained to 99% accuracy to correctly separate the Cats from the not-Cats, in a very small amount of time/iterations.
- Fact: It has a terrible accuracy (70%) on the test set (aka never-seen-before data). Just guessing would have a 50% accuracy if the test set was split 50-50. i.e. the hyperplane is terribly overfit
- Aha! This makes sense because you tried to use 12,288 pixels individually to decide between Cat/not-Cat. (i.e. you had no hidden layers, no “build up of knowledge”, no “higher level constructs”). It only used individual pixels. When looked at from that perspective, it is amazing that it can get 99% accuracy on the training data, and completely un-amazing that it doesn’t generalize to the test data.