… that argues reasoning models were most likely mimicking the data they saw in training rather than actually solving new problems.
2024-12-21, The Wall Street Journal, “The Next Great Leap in AI is behind schedule and crazy expensive”
At least the subheading got it right (“behind schedule and crazy expensive”). But really, does anybody believe that AI is actually solving new problems? That it is doing something more than just mimicking its inputs? AI researchers are just building ELIZA with more hidden layers, so nobody can tell exactly what is going to happen.
But, that was in the 1960s, so I’m guessing that didn’t happen for them, and in any case just doesn’t matter for their “high-complexity” models.
Some facts on the CPU: it is currently #89 on PassMark [53,737] cpubenchmark.net, with a turbo speed of 5.6 GHz and TDP of 125W to 253W. It is 20 cores/28 threads, first seen Q4 2023. 8 of those are “Performance Cores”, 12 are “Efficient Cores”. It is #2 on single-thread rating [4,484] behind the i9-13900K at [4,641].
Just ran across this in a video about Spring Boot by Frank Moley and I thought it deserved a callout.
When creating your Beans (e.g. Controller), you can either:
@RestController()
public class ItemController {
@Autowired;
private ItemService itemService;
Or you can do this:
@RestController()
public class ItemController {
private final ItemService itemService;
@Autowired;
public ItemController(ItemService itemService) {
this.itemService = itemService
}
Both work, but the second one makes JUnit testing way easier. The first one @Autowires the actual field, and is really hard to isolate for test. The second one lets the field stay POJO, and @Autowires the constructor. Both are Spring friendly, but only the second one is JUnit friendly.
Argo CD (github source) is a Continuous Delivery tool done “GitOps” style. Here, that means keeping all of your (Kubernetes) application definitions and configurations under source code control (git).
Assuming you follow GitOps CI/CD best practices of separate repositories (one for application code and a second for your YAML configurations), your development process is likewise split into two discrete problems:
Application Code – build the container images (CI)
Configuration Code – keep your (Kubernetes) configuration files synchronized with the repository (CD)
Argo CD solves the second bullet. And does it pretty well. It supports writing your configuration code in any of: plain YAML, Helm charts. Kustomize, and Jsonnet.
It also supports enforcing that all Kubernetes changes “from the command line” are at least detected (and if desired, automatically rolled back). E.g. if some rogue administrator issues a “kubectl scale –replicas=3 …” command, Argo CD will at least change the status to “Out of Sync”, and is capable of automatically re-synchronizing, and therefore un-doing the change.
Question: do you need separate repositories or just separate directories? i.e. Argo CD takes a repository and a path to configure an “application” – does it ignore commits to files outside of the directory? Answer: yes, it ignores them, so no, you don’t technically need separate repositories. Which means all of the Monorepo fans out there are in luck.
The basic idea is to put a CloudFront distribution in front of your AWS S3 website, create a certificate, and then make sure all of the configuration settings between S3/CloudFront/Route53 agree and work with each other.
AWS S3
Bucket Name
Public
Static website
Notes
www.timtiemens.com
Yes
Disabled
No longer used
cftimtiemensdotcom
Yes
Enabled/Bucket hosting
Bucket policy set to allow access to S3GetObject from Cloudfront
Since all of the files in AWS S3 are auto-deployed from a github repository using “aws s3 sync”, it was simple for me to change the target bucket from “s3://www.timtiemens.com” to “s3://cftimtiemensdotcom”. Note that for AWS S3 static websites, the bucket name has to match (www.timtiemens.com) but for CloudFront, the bucket name can be anything (cftimtiemensdotcom).
AWS CloudFront
Configuration Item
Value
Notes
General
Price Class
Use all edge locations
If there is ever a bill for this, switch to “Use only North America and Europ”
Custom SSL Certificate
ARN of certificate
Selected from dropdown list
Alternate domain names
2
timtiemens.com
www.timtiemens.com
Origins
Origin Domain
cftimtiemens.com
From dropdown choices
HTTP only, port 80
“Name”
is greyed-out, no edit
Behavior
Path pattern
*
Origin and origin groups
cftimtiemensdotcom.s3.us-east-1.amazonaws.com
View
Redirect HTTP to HTTPS
Allowed HTTP methods
GET, HEAD
AWS Certificate Manager
Configuration Item
Value
Notes
Domains
2
timtiemens.com
Requires DNS CNAME confirmation
*.timtiemens.com
Requires same DNS CNAME confirmation
Status
Issued
In Use
Yes
After created, pushed the “Create records in Route 53” button. This creates the required CNAME records in the hosted zone.
AWS Route 53
Record
Type
Value
timtiemens.com
A
Alias, to abcdefghijk.cloudfront.net
www.timtiemens.com
A
Alias, to abcdefghijk.cloudfront.net
various “_xxyyzz”
CNAME
as set by AWS Certificate Manager, for various certificates to be validated by DNS
blog.timtiemens.com
A
34.236.123.127 (separate webserver, not under this CloudFront distribution)
Posted inSoftware Project|Comments Off on Add HTTPS lock to AWS S3
It is fascinating how quickly a simple problem can escalate to a very difficult design problem.
Here are the major pieces needed to frame one of these difficult problems in Tic Tac Toe:
CellValue : X, O, EMPTY
Board : state -> CellValue[9]
Game : board -> Board
Everything is going well until we get to Game.getWinner(). In Tic Tac Toe, the winner is one of four things: X, O, Draw or “unknown/in progress”. The above definitions already includes “X” and “O” – so, can getWinner() return type CellValue? That is a bit awkward, since “EMPTY” makes sense for a Board, but “EMPTY” is a poor name to use for “Draw”. And what string should “EMPTY” return? The “-” to use when printing a board, or “Draw” for printing the winner?
One possible solution is this design:
Player : X, O
CellValue : X(Player.X), O(Player.O), EMPTY
Winner : X(Player.X), O(Player.O), DRAW, INPROGRESS
Board : state -> CellValue[9]
Game : board -> Board
Now, Game.getWinner() returns type Winner, and there are no “null” values floating around to spawn runtime errors. The two similar “Player” concepts are captured explicitly (i.e. “X” can be both a value on a Board, and a winner of a Game), with only a small glitch around things like “Does board.state[3] equal game.getWinner()”? i.e. the sub-problem of comparing a CellValue with a Winner, when they currently share no useful common parent type.
If your goal is to get a good grade in a software engineering class, then use the second design. If your goal is a software project that can generate Kaggle CSV dataset files, the first design will suffice (See tictactoe).
You’re here because you can’t get the unit tests for the Coursera Improving Deep Neural Networks course, Week 3, exercise number 1, to pass. You are trying to correctly implement
def compute_total_loss(logits, labels):
And the unit test keeps failing with an off-by-a-large number (i.e. not the usual “shapes are incompatible” error).
Sorry, this post isn’t going to just give you the answer.
But, since Coursera (instructions and code) and Tensorflow (documentation) have come together to make an incredibly frustrating riddle, this will provide hints on where they went wrong, and thus where you went wrong.
Another guess on why you’re here: you entered “tf.keras.losses.categorical_crossentropy example” into a search engine, and followed the link tf.keras.losses.CategoricalCrossEntropy, and that page shows the first argument as “from_logits=False,”. And you just figured that was close enough.
Yet another guess on why you’re here: you read the instructions – “It’s important to note that the “y_pred” and “y_true” inputs of tf.keras.losses.categorical_crossentropy are expected to be of shape (number of examples, num_classes)”. And you noticed the code gives you “logits” and “labels”, in that order. So Coursera has said “y_pred/y_true”, then said “logits/labels”, and the first documentation link doesn’t even have the first two arguments. But even with all of these naming mis-matches, you still entered the arguments in the order given (implied?) by the instructions.
Note that the V100 is used in the AWS p3.2xlarge instance type. The V100 numbers are in general smaller than the 3080Ti, and with the WSL2 tensorflow 2.12 libraries, the 3080Ti out-performs the V100 on the 50,000 epoch test 736 seconds to 928 seconds – here the 3080Ti is 26% faster.) (Caveat – extremely small test set – only my ml-style-transfer code.)
(Using the “Windows Native tensorflow 2.11” libraries, the V100 out-performed the 3080Ti on the 50,000 epoch test 928 seconds to 1063 seconds – here the V100 is 12% faster).
It looks like the p3.2xlarge has been around since late 2017. It started at $3.06/hour, and is still the same price today (2023/Apr). The V100 prices seems to have dropped from $6,000 in 2019 to $3,500 today.
These are the results from running the ml-style-transfer project on three different AWS EC2 instance types.
Instance Name
$Cost/hour
250 epochs
2,500 epochs
50,000 epochs
p3.2xlarge
$3.06
14s $0.0119
55s $0.0468
928s $0.7888
t2.large
$0.093
849s $0.0219
14,676s $0.3791
293,520s (extrapolated) $7.5826
c5.4xlarge
$0.68
221s $0.0417
2,152s $0.4065
43,040 (extrapolated) $8.1298
Comparing p3.2xlarge GPU with t2.large non-GPU
The p3.2xlarge is 32x more expensive per hour. Yet, for the 2,500 epoch tests, it is 266x faster, which combines to be 8x more cost-effective (e.g. $0.05 versus $0.40 for 2,500 epochs).
The p3.2xlarge also gets results faster (wall clock) – the 50,000 epoch run on p3.2xlarge only took 15 minutes wall clock, yet the projected run on t2.large is 4,892 minutes (over 3 days).
The c5.4xlarge is a “compute optimized” – large vCPU, large RAM. It is 7x the hourly price of the t2.large, and on the 2,500 epoch test, delivers about that much wall clock improvement – so, basically the same cost, but 7x faster delivery of results.
Note: the total test time was approximately 40 minutes on the p3.2xlarge ($2.04) and 280 minutes on the t2.large ($0.44). But, for a mere 5x total cost difference, the p3.2xlarge performed a 50,000 epoch run that would have taken forever on the t2.large.
In contrast, purchasing a RTX 3080Ti for $900 and using it for the 2,500 epoch run took 16 seconds (which is barely slower than the current record-holder p3.2xlarge at 14 seconds).
Next up is to upgrade my AWS account to allow “spot” pricing for p3.2xlarge – if Amazon will allow it for my non-commercial account. The $3.06 on-demand price seems to drop to about $1.01 for spot instances. Update (1 day later): “We have approved and processed your service quota increase request”. So my “EC2->Limits->All P Spot Instance Requests now says “8 vCPUs”, which is enough for one p3.2xlarge instance.
Just FYI: when that AMI is run under a non-GPU machine type, the first run takes an extra 5+ minutes, as the system says “Matplotlib is building the font cache; this may take a moment.” It only does this the first run. (This is an example of a thing that cause differences in “python elapsed time” and “wall clock elapsed time”.)
This is a variation of “Be, Do, Have” (“Be, Do Have” == Be a photographer, Do take a bunch of photos, and then Have/Buy expensive equipment). It records my recent epiphany in Machine Learning. This variation is “Read, Do, Aha”.
I have read a lot of material on machine learning (linear regression, logistic regression, neural nets, supervised learning, CNNs, etc.) I have done some certifications (mainly from Coursera, from Andrew Ng, in the Machine Learning Specialization).
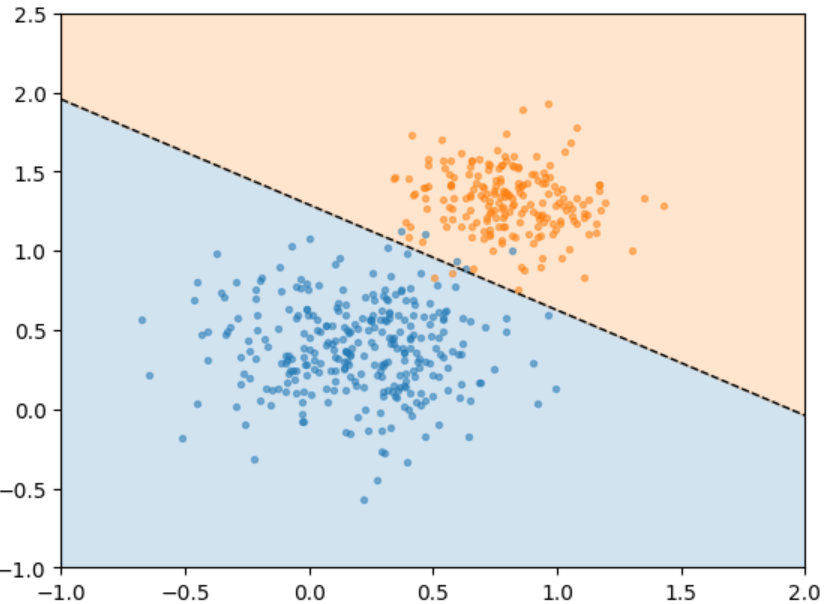
In that course, one of the exercises is to build a simple neural net (simple = two layers total, no hidden layers). So simple it is equivalent to a Logistic Regression model. A very basic plot of a Logistic Regression model is:
In the example above, two inputs (plotted above as x and y) are given a binary classification (blue dot or orange dot), and then a single-line regression is computed, and the graph shaded into blue and orange areas. Thereafter, you can use that line to test the accuracy of known (training) data, and to make predictions on never-seen-before (test) data. In the above example, the training accuracy is quite good, and it seems safe to say the test accuracy will/would be quite good as well.
The course uses “Cat or not-Cat” as the binary class definitions, and flattens a 64x64x3 image into a an input of 12,288 values. After everything is implemented and run against the training data, you have a 12,000+ dimension hyperplane that divides the input space into Cat/not-Cat.
The “Aha!” moment looks like this:
Fact: It can be trained to 99% accuracy to correctly separate the Cats from the not-Cats, in a very small amount of time/iterations.
Fact: It has a terrible accuracy (70%) on the test set (aka never-seen-before data). Just guessing would have a 50% accuracy if the test set was split 50-50. i.e. the hyperplane is terribly overfit
Aha! This makes sense because you tried to use 12,288 pixels individually to decide between Cat/not-Cat. (i.e. you had no hidden layers, no “build up of knowledge”, no “higher level constructs”). It only used individual pixels. When looked at from that perspective, it is amazing that it can get 99% accuracy on the training data, and completely un-amazing that it doesn’t generalize to the test data.